
Week 2: Data Linkage
Goals
- Understand why linkage matters
- Learn how to preprocess data
- Review the basics of linkage methodology
- Understand what can go wrong (and why)
Data linkage is how private sector data companies make money
One of the most important activities for data scientists – and a major reason that they are paid so much – is linking data records. It has many terms in computer science, including “entity or reference resolution”, “disambiguation”, “duplicate detection” and “object consolidation”. The simple reason for its importance is that the better a company can connect a variety of different datasets, the more profitable they tend to be – about 6% more profitable according to some estimates. It enables companies to be more efficient in targeting information, resulting in increased sales and lowered costs. That’s a big reason companies ask for so much personal information – our birthdate or our email address – when we visit a website, buy something at a store, or use a social media app. Those types of link keys make it easier to connect individuals across different datasets. It’s so important to companies, that, for example, in 2022 when Apple changed its privacy settings for app tracking to be opt-in rather than opt-out, Facebook reported that the 2022 cost in sales would be about $10 billion. READ MORE
Data linkage is critical for evidence building
Source: Commission on Evidence based Policymaking
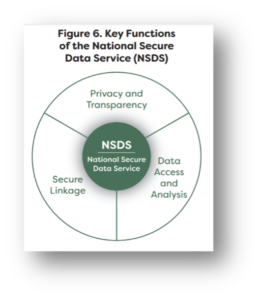
The same reasoning applies to the public sector. As surveys have become more poorer in quality and more expensive, governments have pivoted to using that are trying to target policies to be most helpful to those who need them, without wasting tax payer dollars, need the best data possible. Bringing that point home, the Commission on Evidence based Policymaking identified three key functions of the National Secure Data Service: data access, privacy AND data linkage. The reason is that administrative data are limited in what data are collected. In our use case, education data have no information about the jobs that graduates get so they have to be linked to unemployment insurance wage records if students are to learn what earnings they can expect to get from different majors, or schools want to learn whether their graduates are getting “good”. READ MORE
Understanding the problem
The problem is deceptively simple. There are two files: A and B. The data scientist has to look at each row in data file A and compare it to each row in data file B. Then she has to decide if it’s a match or not. There are a series of challenges. The first is scale. If there are 25 rows in each file, that means that the scientist has to make 625 pairwise comparison. If there are 100 in each file, then there are 10,000. Obviously this is not a problem that can be done by humans. So you have to tell a computer what to do. In telling the computer what to do, you first have to standardize the data in each file (pre-processing). Then you have to decide when to tell the computer what is a match and what is not a match – whether the pair of rows in each of the sets in the figure are correct or not. That requires developing a model which gives the computer a set of rules, or uses probabilistic linkage methods, or uses machine learning methods to make the decision. READ MORE
Setting the stage: Basics (and importance) of preprocessing

An Introduction to Probabilistic Record Linkage (John “Mac” MacDonald https://www.bristol.ac.uk/media-library/sites/cmm/migrated/documents/problinkage.pdf)
Before we can successfully link data from different sources, there is an essential step that must be taken: preprocessing. Preprocessing is the process of cleaning and organizing data to prepare it for further analysis. It’s like preparing ingredients before cooking a meal – we need to wash, peel, and chop before we can start combining them. Similarly, data from different sources might come in different formats, have missing or incorrect values, or contain inconsistencies. Preprocessing helps address these issues, ensuring that the data is in the best possible shape before we attempt to link it. This step is crucial because the quality of the preprocessing work can significantly impact the accuracy and usefulness of the linked data. Poor preprocessing might lead to errors or biases in the final dataset, potentially misleading our analysis. Thus, understanding the basics of preprocessing and its importance is a vital part of the data linkage process. READ MORE
How linkage works: rules, people, and computers
Data linkage is a process that involves rules, people, and computer systems working together. The rules define how data from different sources should be matched or linked. For example, data might be linked based on common identifiers like social security numbers or names. People are involved in establishing these rules, ensuring data quality, and interpreting the results. Computers, of course, perform the actual linking, rapidly comparing large amounts of data according to the defined rules.
One fundamental concept in data linkage is the idea of “joins”. Joins refer to the ways in which data from different sources can be combined. There are four main types of joins: Left, Right, Inner, and Outer. A Left Join includes all the records from the left dataset and any matching records from the right dataset. If there is no match, the result is NA on the right side. A Right Join, conversely, includes all the records from the right dataset and any matching records from the left dataset. If there is no match, the result is NA on the left side. An Inner Join only includes records that have matching values in both datasets. An Outer Join includes all records from both datasets, filling in NAs for missing matches. Understanding these different types of joins and how to use them is a key part of successful data linkage. READ MORE
What can go wrong
Data linkage provides massive opportunities. It provides new ways of describing how individuals move into and out of education, as well as how they move into and out of jobs. But combining data also comes with its own set of challenges. The focus is often on incorrect classifications: 1) false positives – when a decision is made that two records belong to the same person when in fact they belong to different people and 2) false negatives – when the decision is made that two records belong to different people when they in fact belong to the same person (17). But one of the most critical issues to consider is missing data, and its interpretation. When we link data from multiple sources, the chances of encountering missing data increase. In our use case, people might not show up with earnings because they got a job in a different state, for example. There are a LOT of potential biases to look for. READ MORE
Food for thought
As David Hand points out(1)
Challenge 12. Be aware of the risks that are associated with linked data sets and the potential effect on the accuracy and validity of any conclusions. Recognize that quality issues of individual databases may propagate and amplify in linked data. Develop better measures of overall combined data quality. Challenge 13. Continue to develop statistically principled and sound methods for record linkage and evidence assimilation, especially from non-structured data and data of different modes.
Challenge 14. Develop improved methods for data triangulation, combining different sources and types of data to yield improved estimates.
Readings
- Chapter 3 of textbook Record Linkage
- ACDEB Year 2 report Box 2 (p25) and Box 6 (p53) Box 8 (p61)
References
- Hand DJ, Babb P, Zhang L-C, Allin P, Wallgren A, Wallgren B, et al. Statistical challenges of administrative and transaction data. Journal of the Royal Statistical Society Series A (Statistics in Society). 2018;181(3):555-605.
- Binette O, Steorts RC. (Almost) all of entity resolution Links to an external site.. Science Advances. 2022;8(12):eabi8021.
- Chen C, Frey CB, Presidente G. Privacy regulation and firm performance: Estimating the GDPR effect globally Links to an external site.. The Oxford Martin Working Paper Series on Technological and Economic Change; 2022.
- Jonas J. Senzing CEO Jeff Jonas on Entity Resolution in Data Analytics. https://www.youtube.com/watch?v=bNmdzEyb9ac; October 25, 2023.
- Advisory Committee on Data for Evidence Building. Advisory Committee on Data for Evidence Building: Year 2 Report Links to an external site.Washington DC2022.
- Advisory Committee on Data for Evidence Building. Year 2 Report, Supplementary Materials Links to an external site.. In: Office of Management and Budget, editor. 2022.
- Hart N, editor Recommendations of the US Commission on Evidence-Based Policymaking Links to an external site.. 2018 AAAS Annual Meeting; 2018: AAAS.
- Finlay K, Mueller-Smith M. Criminal justice administrative records system (cjars) Links to an external site.. Ann Arbor: University of Michigan, Institute for Social Research. 2021.
- Attewell P, Maggio C, Tucker F, Brooks J, Giani M, Hu X, et al. Early Indicators of Student Success: A Multi-state Analysis. Journal of Postsecondary Student Success Links to an external site.. 2022;1(4):35-53.
- Lane J. Reimagining Labor Market Information: A National Collaborative for Local Workforce Information Links to an external site.. Washington DC: American Enterprise Institute; 2023.
- Kuehn D. Better Data for Better Policy: The Coleridge Initiative in Ohio Links to an external site..
- Kuehn D. Better Data for Better Policy: Lessons Learned from Across the Coleridge Initiative’s Partnerships.https://www urban org/research/publication/better-data-better-policy Links to an external site.. 2022.
- Lohr S. Another Use for A.I.: Finding Millions of Unregistered Voters Links to an external site.. New York Times. Nov 5, 2018.
- Dusetzina SB, Tyree S, Meyer A-M, Meyer A, Green L, Carpenter WR. Background and purpose. Linking Data for Health Services Research: A Framework and Instructional Guide [Internet] Links to an external site.. 2014.
- Joshua T, Stefan B. Record Linkage. Big Data and Social Science: Chapman and Hall/CRC; Links to an external site. 2020. p. 43-65.
- Doidge JC, Harron K. Demystifying probabilistic linkage: Common myths and misconceptions Links to an external site.. International journal of population data science. 2018;3(1).
- Harron K, Mackay E, Elliot M. An introduction to data linkage Links to an external site.. 2016
- administrative data linking and the destruction of statistical power in randomized experiments. Journal of Quantitative Criminology. 2021;37:715-49.
- Abramitzky R, Boustan L, Eriksson K, Feigenbaum J, Pérez S. Automated linking of historical data. Journal of Economic Literature. 2021;59(3):865-918.
- Reamer A, Lane J. A roadmap to a nationwide data infrastructure for evidence-based policymaking. The ANNALS of the American Academy of Political and Social Science. 2018;675(1):28-35.
- Hawley JD. Data Science in the Public Interest: Improving Government Performance in the Workforce: WE Upjohn Institute; 2020.